
GREEDY ALGORITHMS II
Dijkstra’s algorithm
算法图示:Bilibili《最短路径查找—Dijkstra算法》
Dijkstra’s algorithm(迪杰斯特拉算法)是一种用于求解单源最短路径问题的经典算法。该算法可以计算从单个起始节点到图中所有其他节点的最短路径。Dijkstra’s algorithm适用于没有负权边的有向或无向带权图。
算法的基本思想是从起始节点开始,不断扩展当前已知的最短路径,直到到达目标节点或处理完所有节点。该算法使用一个辅助数组(通常称为距离数组)来保存从起始节点到每个节点的最短路径长度。算法的步骤如下:
- 初始化:将起始节点的距离设置为0,其他节点的距离设置为无穷大(表示尚未计算出最短路径)。
- 遍历:从起始节点开始,依次选择当前距离数组中距离最小的节点,记为当前节点。
- 更新:对于当前节点的所有邻居节点,计算通过当前节点到达它们的路径长度,并与距离数组中的当前最短路径进行比较,如果计算出的路径更短,则更新距离数组。
- 标记:将当前节点标记为已处理,继续遍历未被标记的节点,重复步骤2和步骤3,直到所有节点都被处理。
- 完成:当所有节点都被标记后,距离数组中的最短路径就是从起始节点到其他所有节点的最短路径。
Dijkstra’s algorithm保证在没有负权边的情况下能够找到最短路径。然而,如果图中存在负权边,就不能保证得到正确的最短路径,这时候需要使用其他算法,例如Bellman-Ford算法,来处理含有负权边的情况。
1 | import sys |
算法正确性
这个证明过程是关于Dijkstra’s algorithm(迪杰斯特拉算法)在计算最短路径时的正确性。证明使用了归纳法(induction),来说明在算法的每一步中,维持一个不变量(invariant):对于集合S中的每个节点u,d(u)表示从起始节点s到u的最短路径长度。
基础情况(Base case):当集合S中只包含起始节点s时(|S| = 1),因为d(s) = 0,所以该情况是显然成立的。
归纳假设(Inductive hypothesis):假设对于集合S的大小为k(k ≥ 1)时,维持不变量成立,即对于集合S中的每个节点u,d(u)是最短s到u的路径长度。
接下来证明对于集合S的大小为k + 1时,维持不变量仍然成立:
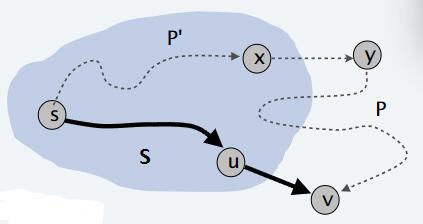
选择下一个节点v加入集合S,并考虑加入S时的最后一条边(u, v)。
加入节点v后,最短s到v的路径长度为π(v),π(v)是在加入v之前S中所有节点与u的最短路径长度加上(u, v)路径长度。
接下来,考虑任意一条从s到v的路径P。我们要证明,该路径的长度不会小于π(v)。
设(x, y)是路径P中第一个离开集合S的边,即从S中的节点x到非S中的节点y的边。然后,P’是从起始节点s到节点x的子路径。
由于节点v是在集合S中添加的最后一个节点,所以在路径P’中,节点x是集合S中最后一个被访问的节点。这意味着在路径P’中,任何从S中的节点到节点x的路径都包含了S中所有节点。
当路径P到达节点y时,它已经比π(v)要长了。这是因为从S中的任何节点到节点v的路径都已经包含在路径P’中,而加上(u, v)边后,路径长度已经达到π(v)。
综上所述,无论路径P如何选择,其长度都不会小于π(v)。因此,当集合S的大小为k + 1时,维持不变量依然成立。
由归纳法的原理,对于任意大小的集合S,都能够保持维持不变量:对于集合S中的每个节点u,d(u)是最短s到u的路径长度。这证明了Dijkstra’s algorithm计算最短路径的正确性。

最小生成树(minimum spanning trees)
最小生成树算法(Minimum Spanning Tree, MST)是一类用于在加权连通图中找到一棵包含所有节点且边权重之和最小的树的算法。MST算法常用于解决优化问题,如网络设计、电力传输等领域。
常见的MST算法有两种:Kruskal算法和Prim算法。
Kruskal算法:Kruskal算法是一种贪心算法,通过不断添加边来构建最小生成树。它的基本思想是将图的所有边按照权重从小到大进行排序,然后依次选择最小权重的边,并将其添加到生成树中,同时要确保生成树不形成环路。直到生成树中包含了所有的节点,算法结束。
Prim算法:Prim算法也是一种贪心算法,它从一个初始节点开始,不断地选择与当前生成树相邻且权重最小的边,并将其加入到生成树中。这样的操作会逐步扩展生成树,直到包含了所有的节点,形成最小生成树。
两种算法的选择依赖于具体的问题和数据结构。Kruskal算法更适用于稀疏图,而Prim算法更适用于稠密图。
基本概念
- Path:通路
- Cycle:环
- Cut:割,割边。割是将图的所有节点划分成两个非空的子集S和V-S(其中V是图中所有节点的集合,S和V-S是两个非空的互斥子集),简言之就是通过割可以将一副连通图变为一副非连通图(或者说两幅图)
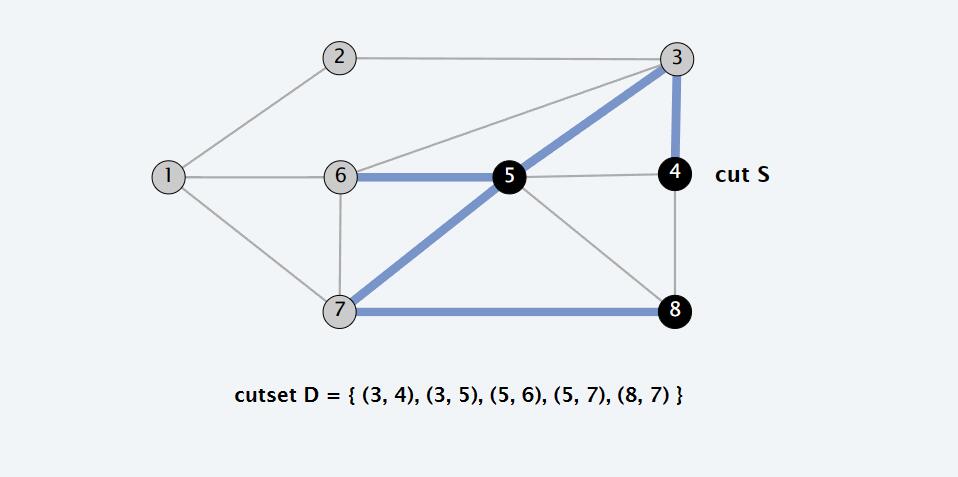
- Cutset:割边集,割集。实现割过程的所有边的集合,在图论中一般是尝试求最小割集
下图就是切割{4,5,8}子集所形成的割集
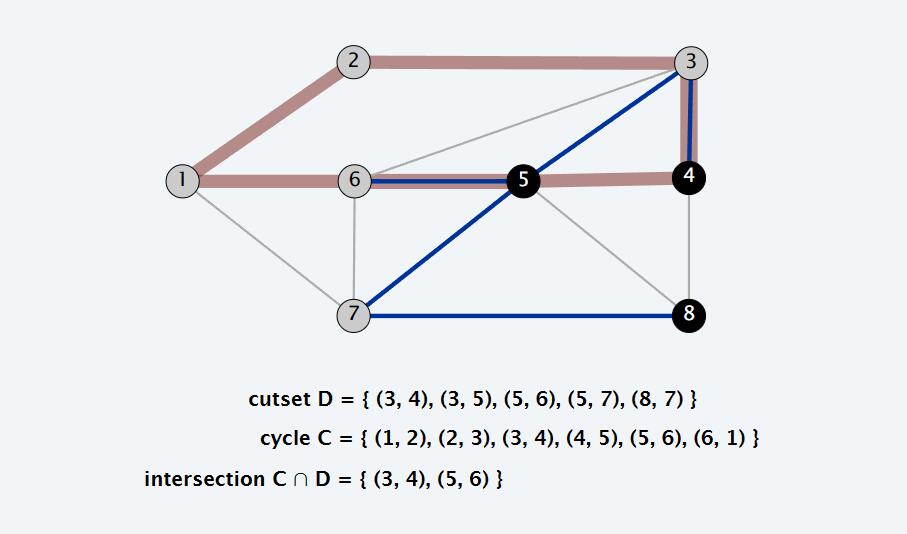
命题:环和割集相交于偶数条边
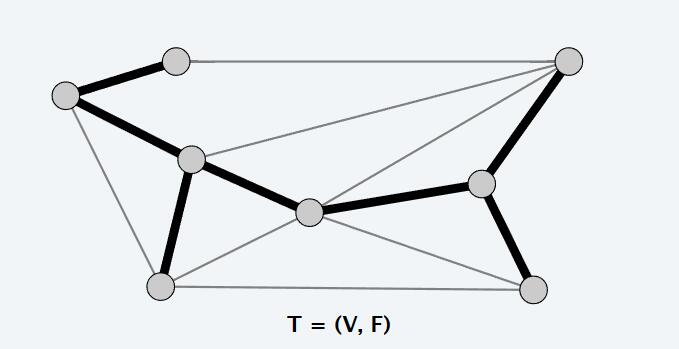
生成树属性
令 T = (V, F) 为 G = (V, E) 的子图。 TFAE:
- T 是G的生成树
- T 是无环且连通的
- T 是连通的并且有 n – 1 条边
- T 是非循环的并且有 n – 1 条边
- T 是最小连接:移除任何边缘都会将其断开
- T 是最大非循环的:任何边的相加都会创建一个循环
- T 在每对节点之间都有一条唯一的简单路径
最小生成树属性
最小生成树本质还是生成树,最重要的一条属性就是边权重之和最小,是最优情况下的生成树
贪心算法(涂色)
- 红色规则:
- 设C是一个没有红边的环
- 选择最大权重的 C 的未着色边缘并将其着色为红色
- 蓝色规则:
- 设 D 为没有蓝边的割集
- 在最小重量的 D 中选择一条未着色的边缘并将其着色为蓝色
Greedy Template
- 不断应用Red rule和Blue rule(非确定性地!)直到所有的边都被着色。
- 这意味着我们在图中找到了所有没有形成环路的边,并且选择了最小的割边,将它们标记为蓝色。
- 最终,所有形成最小生成树的边都被标记为蓝色。
- 注意:在选择蓝色边的过程中,可以在边的数目达到n-1时停止,因为最小生成树总是有n-1条边(其中n是图中节点的数目)。
Prim’s algorithm
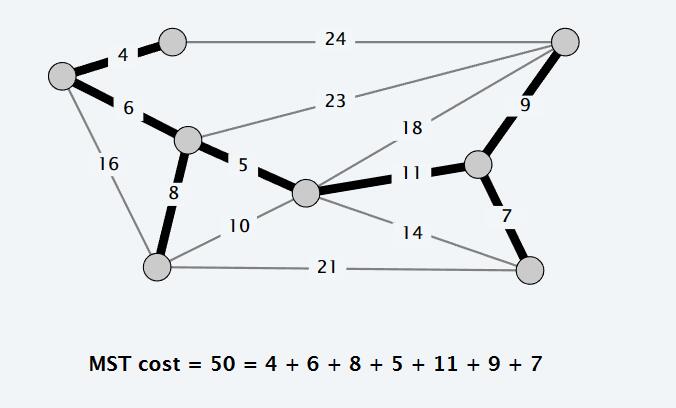
算法图示:Bilibili《最小生成树Kruskal和Prim算法动画演示》
Prim’s algorithm(普里姆算法)是用于解决最小生成树(Minimum Spanning Tree, MST)问题的一种常用贪心算法。它通过逐步添加节点来构建最小生成树,并保证最终生成的树是整个图中权重之和最小的树。
算法步骤如下:
- 初始化:选择一个起始节点作为树的根节点,将其加入到最小生成树中。同时,将所有其他节点标记为未访问状态,并将它们的权重设置为一个较大的值(或者设置为正无穷大)。
- 选取节点:从未访问的节点中选择一个与最小生成树中节点相邻且权重最小的节点,将其加入最小生成树,并将其标记为已访问。
- 更新权重:对于新加入最小生成树的节点,更新其与未访问节点之间的权重值。如果新的权重值比原先的权重值更小,则更新该节点的权重。
- 重复步骤2和步骤3,直到所有节点都被加入最小生成树中。
- 最小生成树构建完成。
Prim’s algorithm的关键在于不断地选取权重最小的节点,并更新相关节点的权重。它保证了每次选择的节点都是与最小生成树相邻且权重最小的节点,从而逐步构建出整个图的最小生成树。
Prim’s algorithm适用于稠密图,即节点之间的边相对较多的情况。在实现上,通常使用优先级队列(最小堆)来维护未访问节点的权重,并通过快速查找和更新节点的权重来加速算法的执行。
算法实现
1 | import heapq |
Kruskal’s algorithm
Kruskal算法是一种常用的贪婪算法,用于寻找连通无向图的最小生成树(MST)。
以下是Kruskal算法的工作原理概述:
初始化: 从一个空的边集合开始,这个集合最终会构成最小生成树。
排序: 将图的所有边按照权重升序排序。
迭代: 逐个遍历排序后的边。对于每一条边:
- 如果将该边加入当前选择的边集合(即已构建的树)不会产生环路,就将边添加到树中。
- 否则,跳过该边,继续处理下一条边。
完成: 重复步骤3,直到最小生成树中的边数等于顶点数减1(因为一个生成树有V-1条边,其中V为顶点数)。
Kruskal算法确保加入的边不会在生成树中引起循环,这使得它成为一种安全的选择。算法会继续添加权重最小的边,同时避免产生循环,从而形成最小生成树。
在算法过程中通常会使用并查集数据结构(也称为并查集数据结构)来有效地检测循环。这个数据结构有助于追踪哪些顶点已经属于生成树,哪些顶点尚未连接。
Kruskal算法高效,其时间复杂度为O(E log E),其中E为图中的边数。这主要归因于排序步骤,它需要O(E log E)时间,而后续步骤需要额外的线性时间。
总之,Kruskal算法通过迭代地添加权重最小的边,同时避免产生循环,从而找到连通无向图的最小生成树。
1 | # 并查集实现 |
上述代码通过定义并查集来简化Kruskal算法过程中的添加边过程和检测环路过程(如果两个点本身就在同一个集合内,就表明它们当前已经有一条能够相互连接的通路,此时再加入它们两个顶点的直接连接路径就会构成环路)
Reverse-delete algorithm
Reverse-delete算法是一种用于找到图的最小生成树(MST)的算法,与Kruskal算法相似。与Kruskal从小到大按权重选择边来构建MST不同,Reverse-delete算法从大到小按权重删除边来构建MST。这个算法首先将所有边按权重降序排列,然后依次删除边,每次删除都会检查是否导致图的断开。如果删除边后图仍然是连通的,说明这条边不是构成MST所必需的,可以被删除。
以下是Reverse-delete算法的步骤:
- 对图的所有边按权重从大到小进行排序。
- 从最重的边开始,依次删除边,并检查删除后图是否仍然是连通的。
- 如果删除边后图仍然是连通的,说明这条边不是MST必需的,将其删除。否则,保留这条边。
- 重复步骤3,继续删除边,直到只剩下V-1条边为止,其中V是图的顶点数。此时,得到的边集合构成了图的最小生成树。
与Kruskal算法不同,Reverse-delete算法不需要检测环路,因为每次删除边后图总是连通的。然而,这个算法需要进行图的连通性检查,以确保删除边后图仍然保持连通。
需要注意的是,Reverse-delete算法可能对于稠密图(边数较多)的效率不如Kruskal算法,因为删除边的过程可能会涉及到多次图的连通性检查。
总之,Reverse-delete算法是一种寻找图最小生成树的方法,通过从大到小按权重删除边来逐步构建最小生成树。
Borůvka’s algorithm
Borůvka’s algorithm(博鲁夫卡算法)是一种用于寻找图的最小生成树(MST)的算法。它是一种并行算法,旨在充分利用多个处理单元或计算机来加速计算。这个算法也被称为Sollin’s algorithm(索林算法)或Sarnowski’s algorithm(萨诺夫斯基算法)。
Borůvka’s算法适用于无向图的最小生成树问题,其基本思想是通过从每个连通组件中选择一个最小权重的边,然后将连通组件合并,最终构建出整个图的最小生成树。
以下是Borůvka’s算法的步骤:
将每个顶点作为一个单独的连通组件。
重复以下步骤,直到只剩下一个连通组件(即构建完整的最小生成树):
对于每个连通组件,选择连接该组件的最小权重的边。
将这些最小权重边所连接的顶点合并为一个新的连通组件。
删除所有不再需要的边。
Borůvka’s算法的一个关键特点是它可以并行地处理多个连通组件,因此在具备多个处理单元或计算机的情况下,它可以实现较高的计算效率。
需要注意的是,Borůvka’s算法可能在稠密图(边数较多)上表现得更好,因为它在每个迭代步骤中可以并行地处理多个连通组件。
虽然Borůvka’s算法在理论上是一个有效的算法,但在实际应用中,由于现代计算机系统和并行算法的复杂性,它可能不如其他算法(如Kruskal、Prim算法)在实践中运行得快速和高效。





