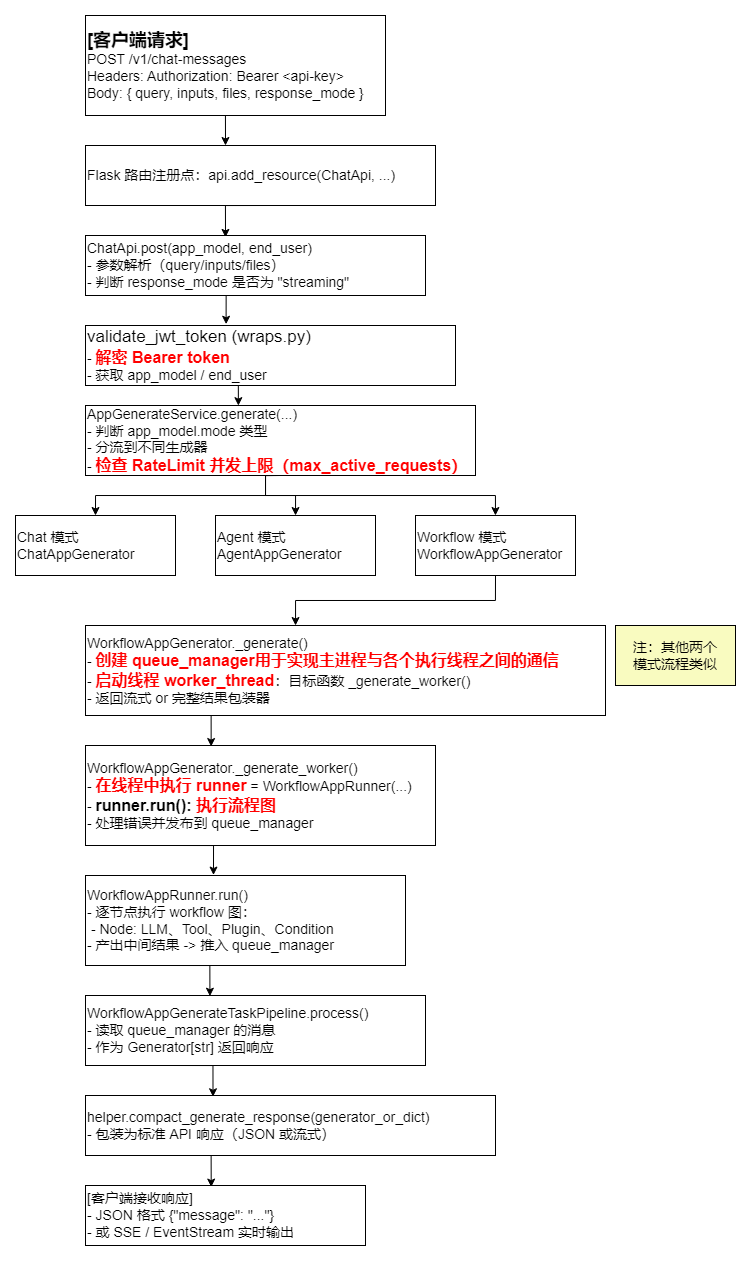
✅ 接入层 token 解密在哪个服务进程?
-
位置:
validate_jwt_token装饰器,位于dify-api主进程中。 -
运行时机:在每一个 HTTP 请求进入业务逻辑前同步执行。
-
作用:
- 从
Authorization: Bearer <api-key>中提取 token - 通过
PassportService().verify(token)解密 - 从数据库查出
app_model与end_user
- 从
-
是否启动新线程:❌ 否,完全在主进程同步执行。
-
是否支持负载均衡:❌ 解密逻辑没有分发,必须完成后才能进入后续流程。
✅ Workflow 执行在哪个服务进程上?
-
入口位置:
WorkflowAppGenerator.generate()→ 启动_generate_worker()线程 -
运行环境:仍然在
dify-api主进程内部,但通过threading.Thread()启动了一个执行线程。 -
执行内容:
- 构建
WorkflowAppRunner实例 - 在子线程中执行
runner.run(),逐节点调用 LLM / 插件 / 判断逻辑 - 运行结果通过
queue_manager推送给主进程
- 构建
-
是否异步线程:✅ 是(每个请求对应一个独立执行线程)
-
是否跨进程调度:❌ 默认不会,执行线程运行在主进程内
✅ Dify 默认负载机制
| 层级 | 是否默认支持 | 描述 |
|---|---|---|
| 请求负载均衡(多进程) | ❌ 未实现 | 需依赖 Nginx / Kubernetes |
| 主进程内调度(多线程) | ✅ 默认每个请求创建一个线程 | 使用 threading.Thread 执行 |
| App 级并发限制(RateLimit) | ✅ 默认启用 | 每个 App 可设置最大并发数 |
| 任务中止机制 | ✅ 支持,通过 queue_manager.stop_flag 控制 | 实现线程中断与资源释放 |
Dify V1 完整执行流程
🔄 补充:企业版支持 LLM 模型层负载均衡
在 企业版 / SaaS 付费版 中,Dify 引入了模型层的负载均衡功能,用于解决高并发下 LLM API 的速率限制问题。用户可在模型配置中添加多个 API 凭据并开启分发功能。
- 支持配置多个 API Key(如多个 OpenAI 凭据)
- 默认使用 Round-robin 分发策略
- 若触发速率限制,自动冷却 1 分钟
- 管理界面支持凭据启停与删除
📖 详情文档见:Dify 模型负载均衡官方指南