连续分配管理方式
连续分配:指系统为用户进程分配的必须是一个连续的内存空间
单一连续分配
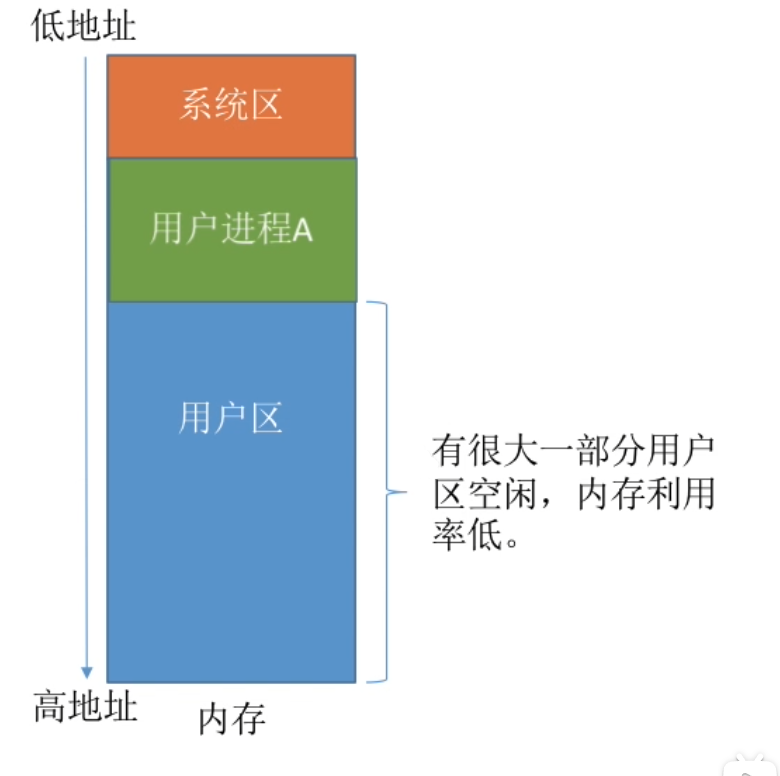
在单一连续分配方式中,内存被分为系统区和用户区。
- 系统区通常位于内存的低地址部分,用于存放操作系统相关数据
- 用户区用于存放用户进程相关数据。内存中只能有一道用户程序,用户程序独占整个用户区空间。
优缺点
- 优点:实现简单,无外部碎片,可以采用覆盖技术扩充内存,不一定需要内存保护机制
- 缺点:只能用于单用户,单任务的操作系统中,有内部碎片,存储器利用率极低
内部碎片:分配给某进程的内存区域中,如果有些部分没有用上,这些内存部分就被称为“内部碎片”
固定分区分配
20世纪60年代出现了支持多道程序的系统,为了能在内存中装入多道程序,且这些程序之间又不会相互干扰,于是将整个用户空间划分为若干个固定大小的分区,在每个分区中只装入一道作业,这样就形成了最早的、最简单的一种可运行多道程序的内存管理方式。
固定分区分配又可以细分为分区大小相等与分区大小不等两种情况
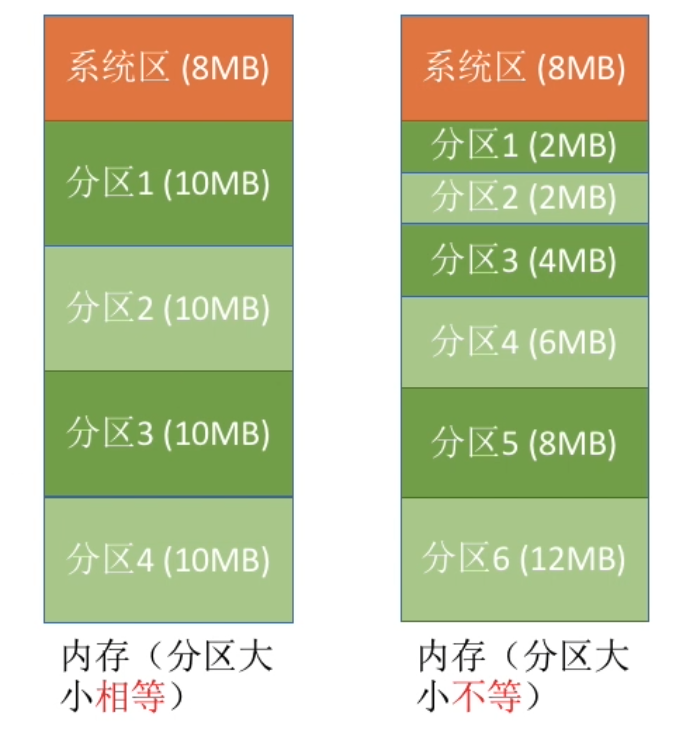
针对分区大小不等的情况,系统为了维护分区状态以及管理各个分区,需要建立一个数据结构—分区说明表:
| 分区号 | 大小(MB) | 起始地址(M) | 状态 |
|---|---|---|---|
| 1 | 2 | 8 | 未分配 |
| 2 | 2 | 10 | 未分配 |
| 3 | 4 | 12 | 已分配 |
| … | … | … | … |
当某用户程序要装入内存时,由操作系统内核程序根据用户程序大小检索该表,从中找到一个能满足大小的、未分配的分区,将之分配给该程序,然后修改状态为“已分配”。
优缺点
- 分区大小相等:
- 优点:适用于计算机控制多个相同对象的场合
- 缺点:缺乏灵活性
- 分区大小不等:
- 优点:实现简单,无外部碎片,增加了灵活性,可以按照不同大小的进程需求,根据系统中运行的作业大小情况进行划分
- 缺点:当用户程序过大时,可能所有分区都不能满足需求,此时不得不采用覆盖技术解决,但这又会降低性能,会产生内部碎片,内存效率低
动态分区分配
动态分区分配又称为可变分区分配。这种分配方式不会预先划分内存分区,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。因此系统分区的大小和数目是可变的。(eg:假设某计算机内存大小为64MB,系统区8MB,用户区共56 MB..)
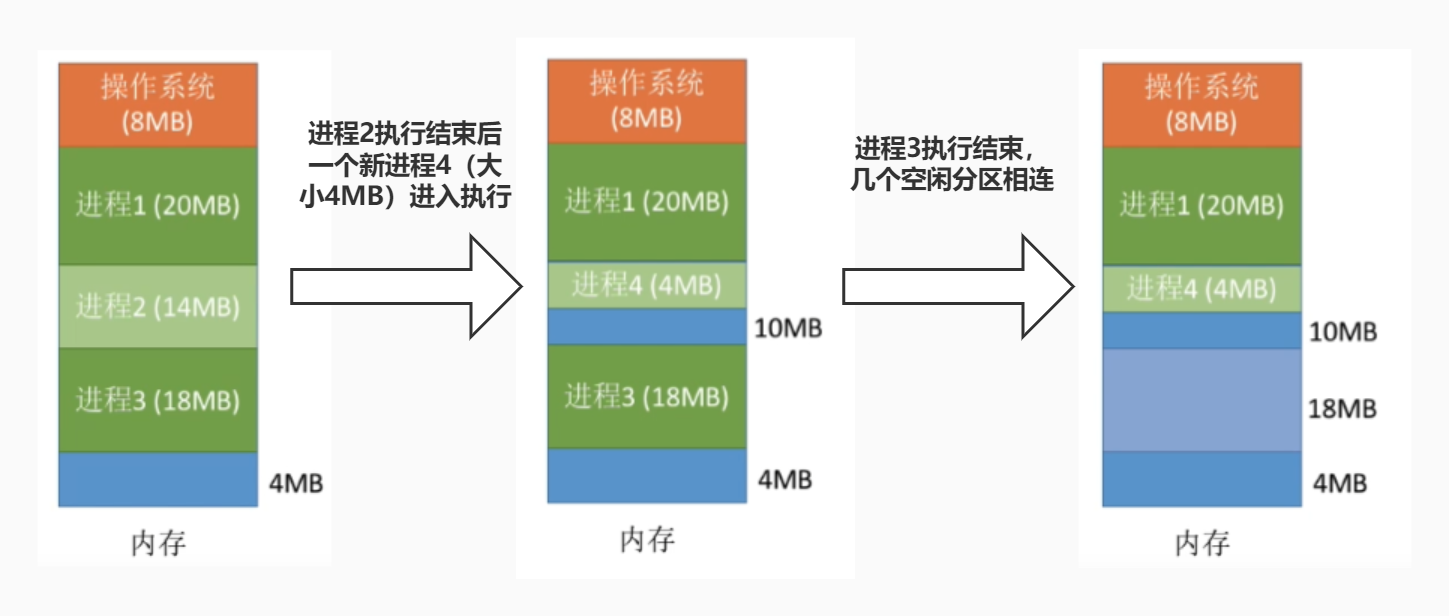
动态分区分配中首先我们要考虑“系统要用什么样的数据结构记录内存使用情况?”,另外从进程4进入过程中我们看到,有多个空闲分区满足它的要求,所以我们要考虑“当很多空闲分区都能满足需求时,应该选择哪个分区进行分配”,最后我们看到,在进程3执行结束后,几个空闲分区在物理位置上相连,是否要将它们几个结合,所以我们还需要考虑“如何进行分区的分配与回收”
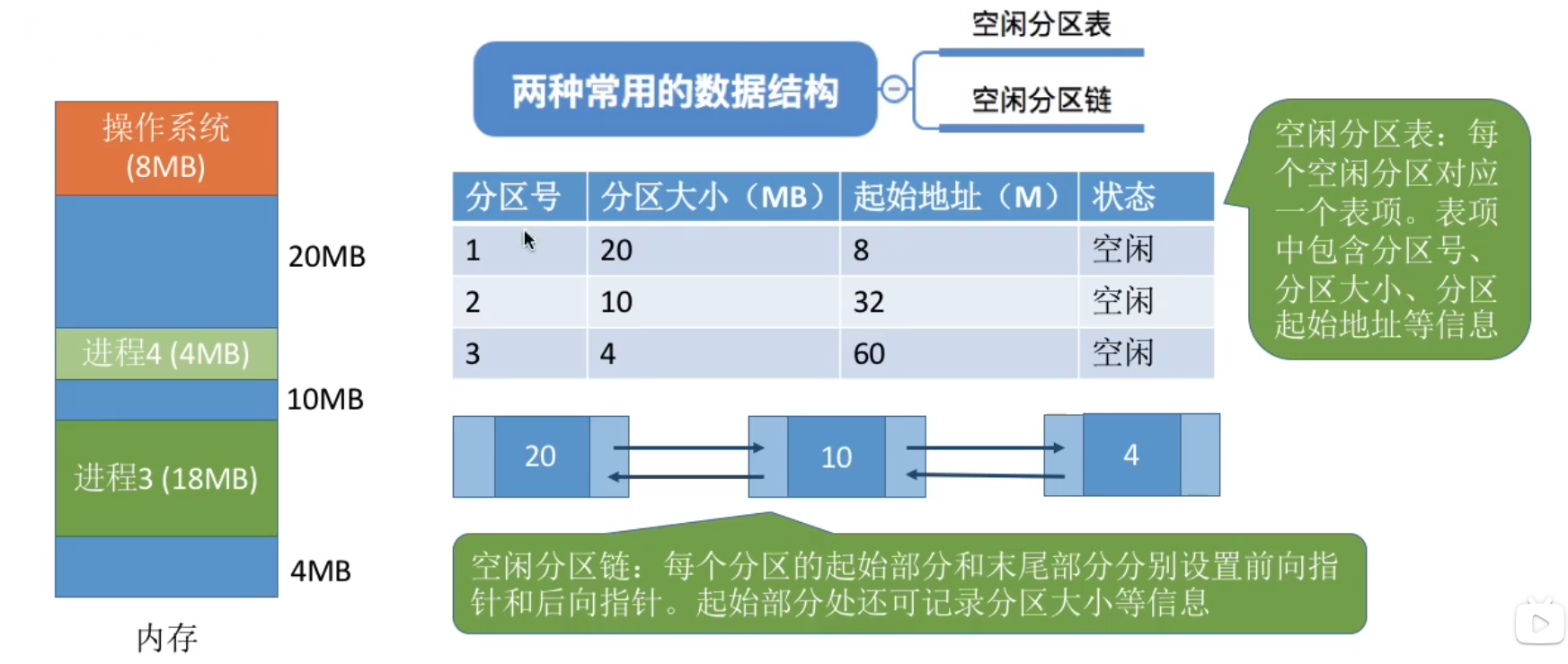
系统要用什么样的数据结构记录内存使用情况?
最长采用两种常用的数据结构:空闲分区表和空闲分区链
当很多空闲分区都能满足需求时,应该选择哪个分区进行分配
把一个新作业装入内存时,须按照一定的动态分区分配算法,从空闲分区表(或空闲分区链)中选出一个分区分配给该作业。由于分配算法算法对系统性能有很大的影响,因此人们对它进行了广泛的研究。并在此基础上完成了多种动态分区分配算法
如何进行分区的分配与回收
首先是在分配过程中,可能会出现将进程大小与空闲分区大小不相等的情况,此时对于空闲分区表来说就需要修改对应分区大小以及起始地址。也可能出现进程大小恰好等于空闲分区大小的情况,此时就需要删除空闲分区表中的一行,对空闲分区链也同理
而对于回收过程,需要注意的就是,如果一个进程执行结束,其所在分区由分配状态变为空闲状态,就需要检查该分区前后是否还存在空闲分区,如果前方或后方存在空闲分区,就需要将他们合并为一个分区,并修改空闲分区表。如果前后都不存在空闲分区,则需要在空闲分区表中新增一行
动态分区分配没有内部碎片,但是有外部碎片。
- 内部碎片:分配给某进程的内存区域中,如果有些部分没有用上。
- 外部碎片:是指内存中的某些空闲分区由于太小而难以利用。
- 紧凑技术:如果内存中空闲空间的总和本来可以满足某进程的要求,但由于进程需要的是一整块连续的内存空间,因此这些“碎片”不能满足进程的需求。可以通过紧凑(拼凑,Compaction)技术来解决外部碎片。
动态分区分配算法
首次适应算法
- 算法思想:每次都从低地址开始查找,找到第一个能满足大小的空闲分区。
- 如何实现:空闲分区以地址递增的次序排列。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
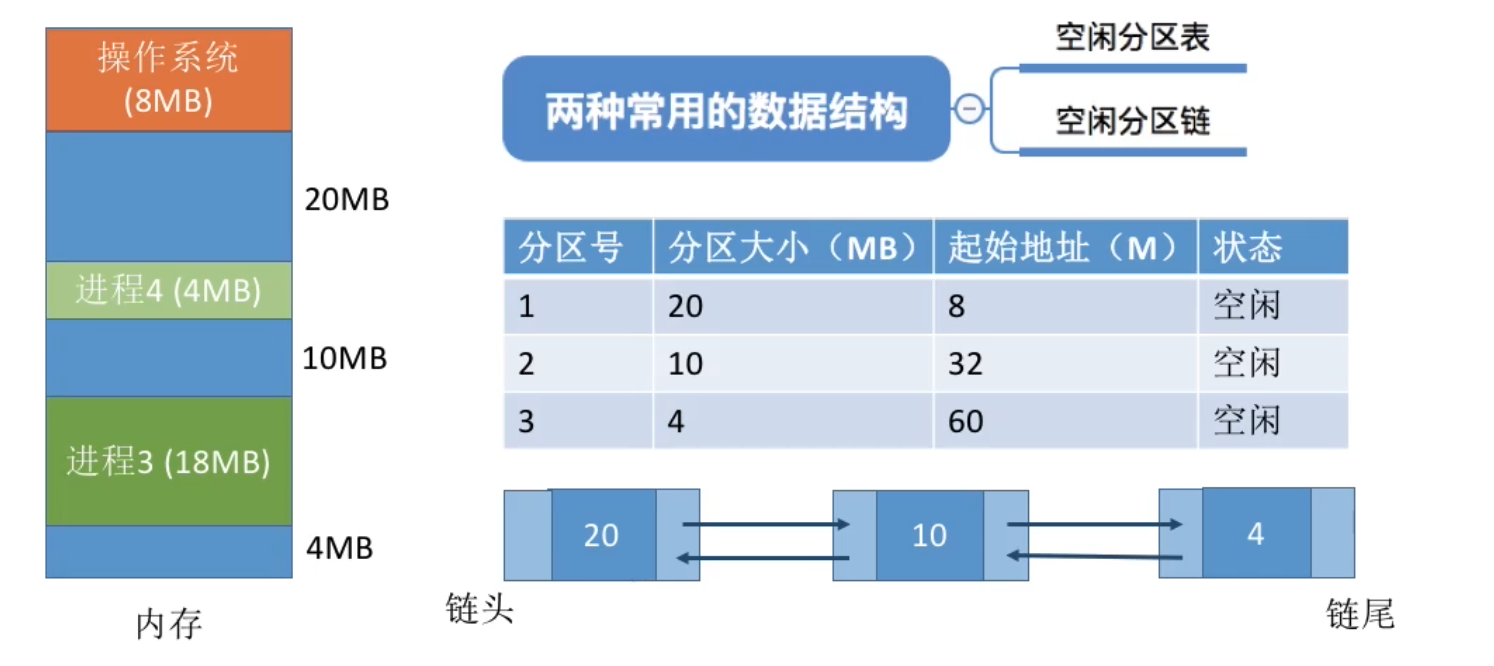
最佳适应算法
- 算法思想:由于动态分区分配是一种连续分配方式,为各进程分配的空间必须是连续的一整片区域。因此为了保证当“大进程”到来时能有连续的大片空间,可以尽可能多地留下大片的空闲区,即优先使用更小的空闲区。
- 如何实现:空闲分区按容量递增次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
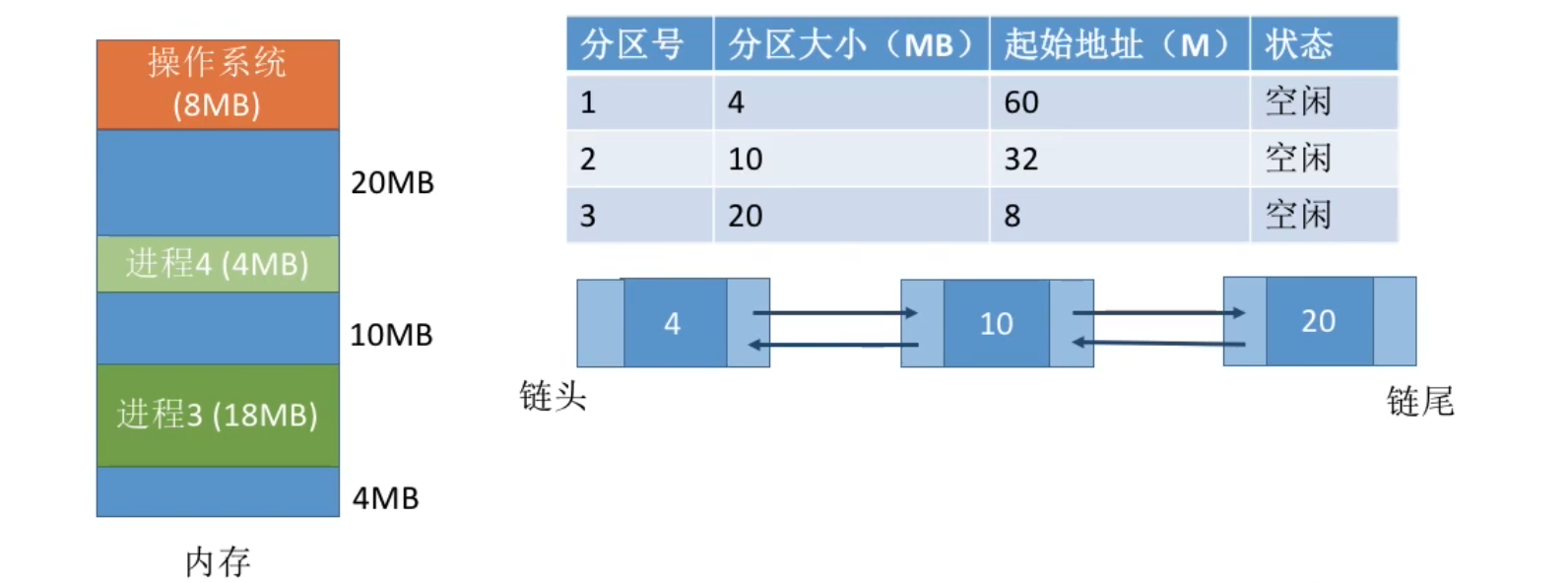
缺点:每次都选最小的分区进行分配,会留下越来越多的、很小的、难以利用的内存块。因此这种方法会产生很多的外部碎片。
最坏适应算法
又称最大适应算法(Largest Fit)
- 算法思想:为了解决最佳适应算法的问题—即留下太多难以利用的小碎片,可以在每次分配时优先使用最大的连续空闲区,这样分配后剩余的空闲区就不会太小,更方便使用。
- 如何实现:空闲分区按容量递减次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
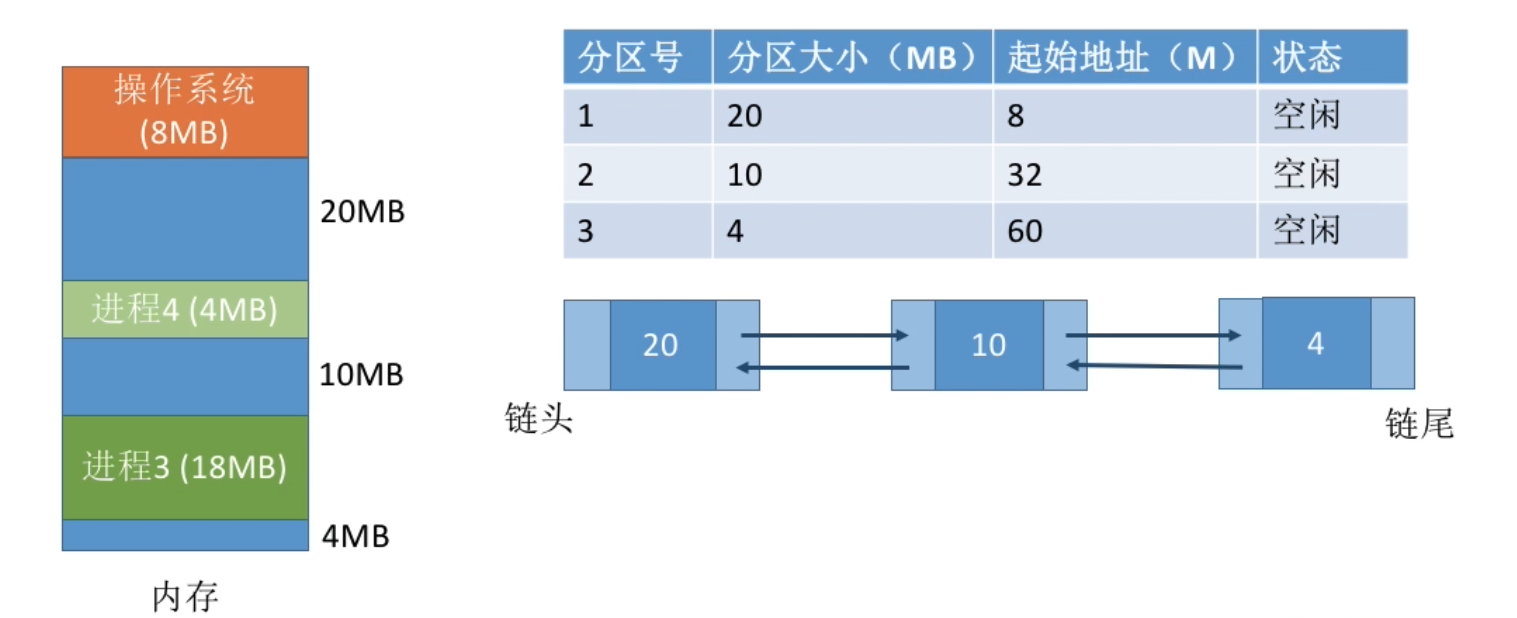
缺点:每次都选最大的分区进行分配,虽然可以让分配后留下的空闲区更大,更可用,但是这种方式会导致较大的连续空闲区被迅速用完。如果之后有“大进程”到达,就没有内存分区可用了。
临近适应算法
基于首次适应算法的一种改良
- 算法思想:首次适应算法每次都从链头开始查找的。这可能会导致低地址部分出现很多小的空闲分区,而每次分配查找时,都要经过这些分区,因此也增加了查找的开销。如果每次都从上次查找结束的位置开始检索,就能解决上述问题。
- 如何实现:空闲分区以地址递增的顺序排列(可排成一个循环链表)。每次分配内存时从上次查找结束的位置开始查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
首次适应算法每次都要从头查找,每次都需要检索低地址的小分区。但是这种规则也决定了当低地址部分有更小的分区可以满足需求时,会更有可能用到低地址部分的小分区,也会更有可能把高地址部分的天分区保留下来(最佳适应算法的优点)
邻近适应算法的规则可能会导致无论低地址、高地址部分的空闲分区都有相同的概率被使用,也就导致了高地址部分的大分区更可能被使用,划分为小分区,最后导致无大分区可用(最大适应算法的缺点)
四种动态分配算法比较
| 算法 | 算法思想 | 分区排列顺序 | 优点 | 缺点 |
|---|---|---|---|---|
| 首次适应 | 从头到尾找适合的分区 | 空闲分区以地址递增次序排列 | 综合看性能最好。算法开销小,回收分区后一般不需要对空闲分区队列重新排序 | |
| 最佳适应 | 优先使用更小的分区,以保留更多大分区 | 空闲分区以容量递增次序排列 | 会有更多的大分区被保留下来,更能满足大进程需求 | 会产生很多的,难以利用的碎片;算法开销大,回收分区后可能需要对空闲分区队列重新排序 |
| 最坏适应 | 优先使用更大的分区,以防止产生太小的不可用的碎片 | 空闲分区以容量递减次序排列 | 可以减少难以利用的小碎片 | 大分区容易被用完,不利于大进程:算法开销大(原因同上) |
| 临近适应 | 由首次适应演变而来,每次从上次查找结束位置开始查找 | 空闲分区以地址递增次序排列(可排列成循环链表) | 不用灭磁都从低地址的小分区开始检索,算法开销小 | 会使高地址的大分区也被用完 |